機械学習の検証(リーク、混同行列)について
こんにちは、Chihoです。
今日はインターンで機械学習の検証をやる機会があったのでその復習。
モデルとかちょっと触れたことはあっても検証をちゃんとやったことないのでいい勉強になりました。それでは行きましょう!
リークとは
本来考慮すべき点が漏れていることを言います。
今回検証した例では学習用データ、予測データに分けた時に学習用データに含まれているものが予測データに含まれていないか確認しました。
学習用データにすでに入っていればそりゃ正解するわな…って感じですね。
ほかにも予測データの要素内に答えが混じっていないか、未来を予測するのに今分からない、未来で分かる情報が入っていないかなどを考えます。
これをやらないとモデル構築して予測しても正しいものにはなりませんね。
混同行列とは
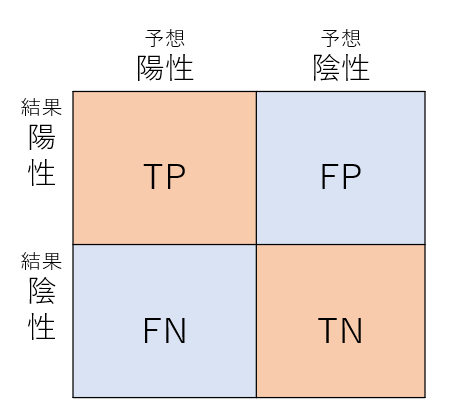
ここでは「インフルエンザが陽性か、陰性か」のような分類が2つだけのパターンを説明します。ちなみに多クラス分類についても混同行列は対応しています。
この予測は陽性、陰性の2つのパターンのみに分類されると思われがちですが、実は4つに分類できます。
真陽性(TP)
今回の例で言うならば、インフルエンザの陽性だったと予想して、実際に陽性だったパターンがこれに当たります。
真陰性(TN)
こちらはインフルエンザが陰性だったと予想して、実際に陰性だったパターン。
真陽性、真陰性については予想と答えはあっています。
偽陽性(FP)
ここからは予想が違ってきます。
偽陽性ではインフルエンザが陽性だと予想したのに実際は陰性だったパターンが当てはまります。
偽陰性(FN)
こちらでは陰性だと予想したのに陽性だったパターン。感染症で言えば一番危ないやつですね。
一口に合ってる、合ってないといってもこれだけのパターンが考えられます。
以下はまとめの図。
精度の評価
続いてそのモデルの精度を評価していきます。
精度の評価なんて正解率を計算すればいいじゃん!って思う人もいるかもしれませんがそれは要注意。
インフルエンザの例を使うなら「今の時期、インフル流行ってるし風邪っぽいやつはみんなインフルでいいよね!」って言ってるやつがいたらどうでしょうか…

確かに流行ってるのでおそらく正解率は高いかもしれません。でも偽陽性、つまり適当に陽性だと言われたけど実際には陰性の人もいるわけです。どこかに偏りがあるとそのモデルは学習時に偏った傾向をつかんでそれのみで分類してしまうかもしれません。その時に以下の3つの評価指標が役に立ちます。
Accuracy(正解率)
これが一番しっくりくるやつ。
どれだけ予測と事実が一致してるかの指標です。
(TP + TN) / (TP + TN + FP + FN)
普通に全体で正解したやつを割ればいい。
Recall(再現性)
インフルエンザの例で言うと、陽性の人を予測の時点でどれだけ当てられたかになります。
結果的に陽性だった人のみ考えます。その中から予想の時点で陽性だった人の割合を算出する指標です。
TP / (TP + FN)
Precision(適合性)
今度は陽性だと予想した中で本当に陽性だった人を考えます。
適当にみんな陽性としてしまった場合、ここの割合が低くなるのでモデルが不適切であるということが分かります。
TP / (TP + FP)
基本この3つのバランスを見て検証を行うようです。
とりあえず今日はここまで。次回くらいに実際にPythonで書いて動かしてみます。