『COMPUTERS AND INTRACTABILITY』を読んで生まれた疑問を解決する
久しぶりに更新します。
最近『Computers and Intractability』という、NP完全問題に関する本を読んでいました。
いくつか分からない単語とかがあり、それらを一応?解決したので覚書として記録します。多項式階層以下が分からなかった感じですが、復習としてクラスPやNP、NP完全についても触れておきます。
クラスP
決定性Turing機械で、多項式時間で解ける(yesかnoかの判別がつく)問題のクラス。
計算量の関数yが、入力xに関して、y=xとか、y=x^2、y=logxとかの式で表せる。
偶数の判定とかはクラスPに属する。
クラスNP
決定性Turing機械で、答えが与えられたときに、その答えが正しいかどうかが多項式時間で判別できる問題のクラス。
問題を解くこと自体は、指数時間掛かってもいい。例えば計算量の関数が、y=2^xとかになってもいい。
NP完全
以下の二つの条件を満たす問題。
- クラス NP に属するすべての問題が、その問題に多項式時間内帰着可能である。
- その問題がクラスNPに属している。
1だけ満たすときは、NP困難という。NP困難問題はクラスNPに属していないので、yesかnoかの判定問題ではない。
あるNP完全問題は他の任意のNP完全問題に言い換えることができる。
例としては、巡回セールスマン問題、ハミルトン閉路など。
多項式階層
ここからがよく分からなくて調べたところ。間違ってたら教えてください。
A^Bを、クラスAのTuring機械にクラスBの何らかの問題を解くオラクルを付加して、強化したもので解ける決定問題の集合とする。例えば、P^NPは、NPを解くオラクルを備えることで、多項式時間で解ける問題のクラス。
P=NPが証明されると、これらのクラスもすべてイコールになる。
NP-easy
日本語で書かれたものが少なく、苦労した部分です。
NPにおけるある決定問題について、オラクルを持つ決定性Turing機械によって多項式で解けるもの。つまり、P^NP?
これ、NP完全と何が違うのか全く分かりません……。一つのNP完全問題がNP-easyとなるなら帰着できるのですべてNP-easyとなるのでは?
そういう感じだからほとんど本で見かけないのかもしれないですね。
ちなみにNP-easyとNP-hard(NP困難)を同時に満たす問題は、NP-equivalentというそうです。例としては巡回セールスマン問題が挙げられていました。
疑似多項式時間アルゴリズム
計算時間が、入力に必要なビット長ではなく、入力の数値の多項式時間で表されるアルゴリズムのこと。
一般的に、計算時間の関数の入力は、Turing機械におけるステップ数などです。しかし、ステップ数的には多項式時間でも、入力に必要なビット長で関数を表すと、指数時間になる場合もあります。
例えば、ステップ数で表すと、O(n^4)であっても、ビット長で表すとO(2^4x)となるアルゴリズムとか。領域関係の計算クラス(DLとかPSPACEとか)もあるけど、あれは計算全体を指すので入力だけに着目すると疑似多項式時間アルゴリズムに属するようです。
強力なNP完全性
計算時間の関数を、入力のビット長でなく、入力の数値で表しても指数関数となるもの。おそらくクラスNPに属する問題は、入力が何であれ、答えの正しさは多項式時間で求めることができるけど、解くこと自体は多項式で表せないのだと思います。(P=NPが証明されない限り)
NP完全性に強力かどうかがあるのは違和感があるんですけど……。同じNP完全同士であれば帰着可能な時点でNP完全問題に差はないのだと思っていたのですが違うのでしょうか。
とりあえず分からない単語はできるところまで調べてまとめてみました。タイトルで解決するとか言っておきながら疑問が生まれ続けてますけど。
もう少し英語が得意になって再チャレンジするか、辛抱強く追いかけて分かったことがあったら追記したいと思います。
IBM Quantumを触ってみる
こんにちは、Chihoです。
大学院に入学して、三か月…。
卒論のこととか色々あったけど、授業や研究に忙しい感じでした…。
今日は量子ゲート方式であるIBM Quantumを触ってみたので、その覚書です。
ちなみに参考はInterfaceの2022年6月号。ちょっぴり引っかかったところもあったのでその辺を重点的に。
量子コンピュータとは
簡単に言えば、量子力学に基づいたコンピュータ。
今あるコンピュータ(古典コンピュータ)は古典力学に基づいています。そこを変えるようなコンピュータ。実際に実機もあるので触ろうと思えば触れる。
完成すると何が嬉しいかというと、今までびっくりするくらい時間のかかる計算が速くできると信じられていることです。(前IBMが言ってたのは、スパコンが1万年かかる計算が3分ちょっとでできるそう…)
実現がなかなか難しいけど、完成したら機械学習とかシミュレーションとかに応用できる。暗号面だとデメリットもあるけど…
詳しいこと書いてるとキリがないので、とりあえず計算が速くなると思われるコンピュータだと思えばいいでしょう、きっと。
量子ゲート方式
量子コンピュータと言えばこれ。歴史も長い。今回はこっちを触ります。
簡単に言えば、今のコンピュータみたいに汎用的な量子コンピュータ。論理ゲートの代わりに量子ゲートを使います。
量子アニーリング方式を聞いた後の方が分かりやすいかも。
IBMとかGoogleが頑張って開発しています。昔はNECとかも頑張っていて、量子ビットを実現させたのは日本だったりする。
IBMのやつが一部タダで使えます。量子ビット数は125ビットくらい?
量子アニーリング方式
商用化されていて、社会でよく広まっているのはこっちかも。
量子ゲート方式とはそもそもが違います。イジングモデルの基底状態探索問題を解くための専用機。汎用性がない代わりに大規模化しやすい。
こいつを使うためには、解きたい問題を基底状態探索問題の形に変えなきゃいけないです。
カナダのD-Waveが有名。日本発案のアイデアだったりします。だからかもしれないけど、日本企業は量子アニーリング方式を結構やってる気がする。
なぜかNECも、こっちに注力してる。
D-Waveのやつは月に1分間無料で使えます。量子ビットは約5000ビット。ゲート方式とは比べ物にならない規模です。
今実現化されているのはアニーリング方式だけど、きっと将来はゲート方式が主流になるに違いないと思っています。(今のコンピュータも似たような歴史を辿っているので…)
前置きが長くなりましたが、実際に触ってみます。
IBM Quantumを触ってみる!!
実行環境
- Windows11
- AnacondaのJupyter(仮想環境は使ってないです。)
アカウント作成
まずはIBMのサイトでアカウントを作成します。
普通にやってればOK。
自分のダッシュボードにAPI Tokenがあるのでコピーしておきます。
これがないと実機が使えない。
必要なライブラリを入れる
2つ入れれば動きます。どっちも現時点ではcondaで入らないので、pipで入れるしかないです。
- qskit
シミュレーションしてみるとき、実機を触るとき、両方で使います。
- pylatexenc
結果をビジュアルとして出すときに必要??
Interfaceでは特に書いてなかったけど入れないと動かないです。
触ってみた
細かいコード等は、Interfaceにあるので書きません。
ここら辺見るとコードは書いてあるでしょう…
実行にはそこそこ時間がかかります。というか、自分自身D-Waveのアニーリングばっかりだったので…(あれは一瞬で終わる)
混み具合がかなり影響してそうです。自分の時は300人くらいいたかな…
混んでないやつはビット数が少なかったり、有料だったりするっぽい。
無料だと時間があるときに遊ぶ程度かな。あとはシミュレーション使ってみるしかない。そういった意味ではD-Waveはそこそこ使えるのだと改めて認識しました。
ゲートの説明
次は、Interfaceで説明がなかったと思われるゲートについて自分用に書いていきます。
- Xゲート
NOTゲートのこと。具体的には以下のように書ける。
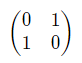
ユニタリ行列であることも確認できる。
- Hゲート
Hadamard行列のこと。具体的には以下のように書ける。
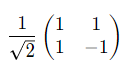
これを各ビットに適用すると、0,1が同じ確率で出力される。
こちらもユニタリ行列。
とりあえず今回はこんな感じ。記事書いてる間に結果出るかなと思ったけどまだ出ない。(´;ω;`)
PowerPointで作った図をTexへ(ベクター図)
こんにちは、Chihoです。
卒論提出が1月頭のため、卒論に追われています…
そんな中、指導の先生から卒論に入っている図がラスター画像だからベクター画像に直せという指示が出ました。
個人的に色々試行錯誤したので後々のために書き残しておこうと思います。
別のサイトを見るとパッケージのインストールとか仮想プリンタ使ってました。うまくいかなかったのと冒険する時間はなかったので手っ取り早く…
ちなみに図はPowerPointで作っていて卒論はTexで書いています。今回はLibreOfficeを使って.epsの形式に図をしていきます。
なお、LibreOfficeは必須なのでない方はインストールを。無料で使えて便利です。
以下がURLです。
用語の説明
ラスター画像
ピクセル、つまり小さな点の集まりで図を表現します。拡大すると分かりやすく、ギザギザになるのがラスター画像です。点の集合体なのでグラデーションとかの表現が得意。
写真とかの拡張子、.pngや.jpgはラスター画像です。
ベクター画像
関数で図を表現します。拡大しても直線や曲線がきれいなままです。ただし、グラデーションとかの表現はラスター図に比べると劣ります。
卒論とか論文の図は基本ベクター図です。拡張子は.epsや.svg とか。
PowerPointで図を作る
早速やっていきましょう。
まずはPowerPointで図を作ります。以下の図を例として説明をしていきます。
ちなみに先生に注意される以前にもLibreOfficeを使って図を変換してました。やり方としてはPowerPointで作った図をコピペしてやってましたが不具合が…
具体的には以下のような不具合がありました。
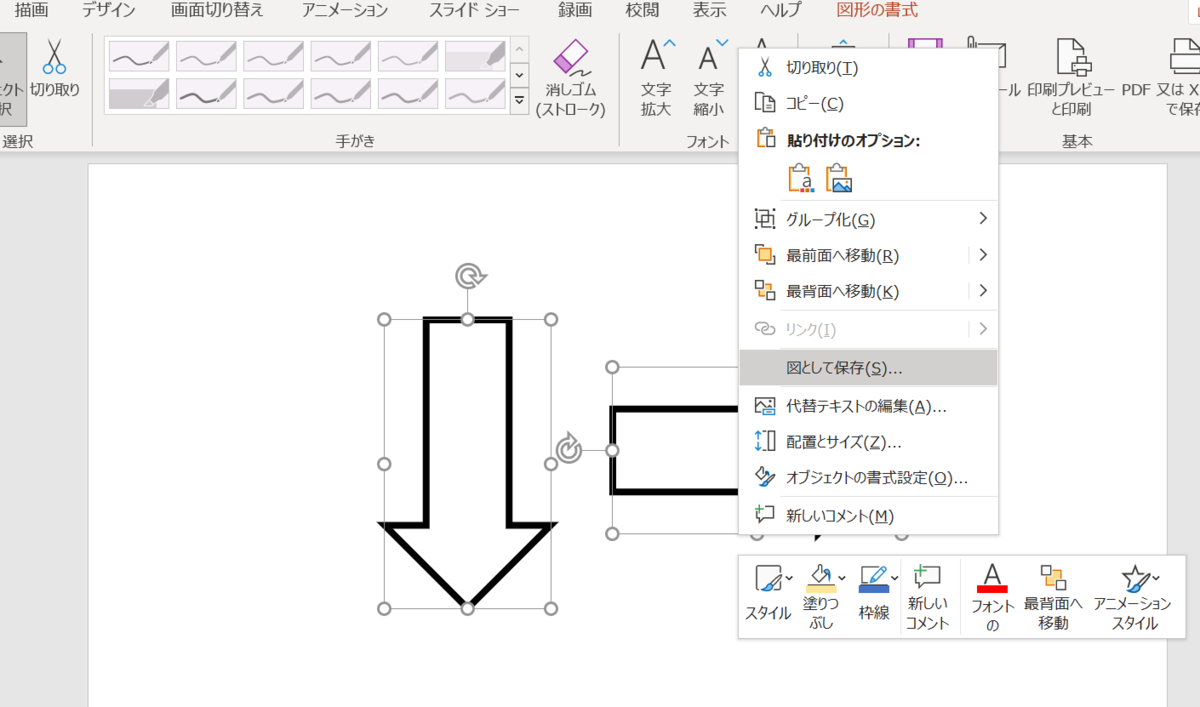
なので別の方法です。作った図を選択して右クリック→図として保存を選びましょう。
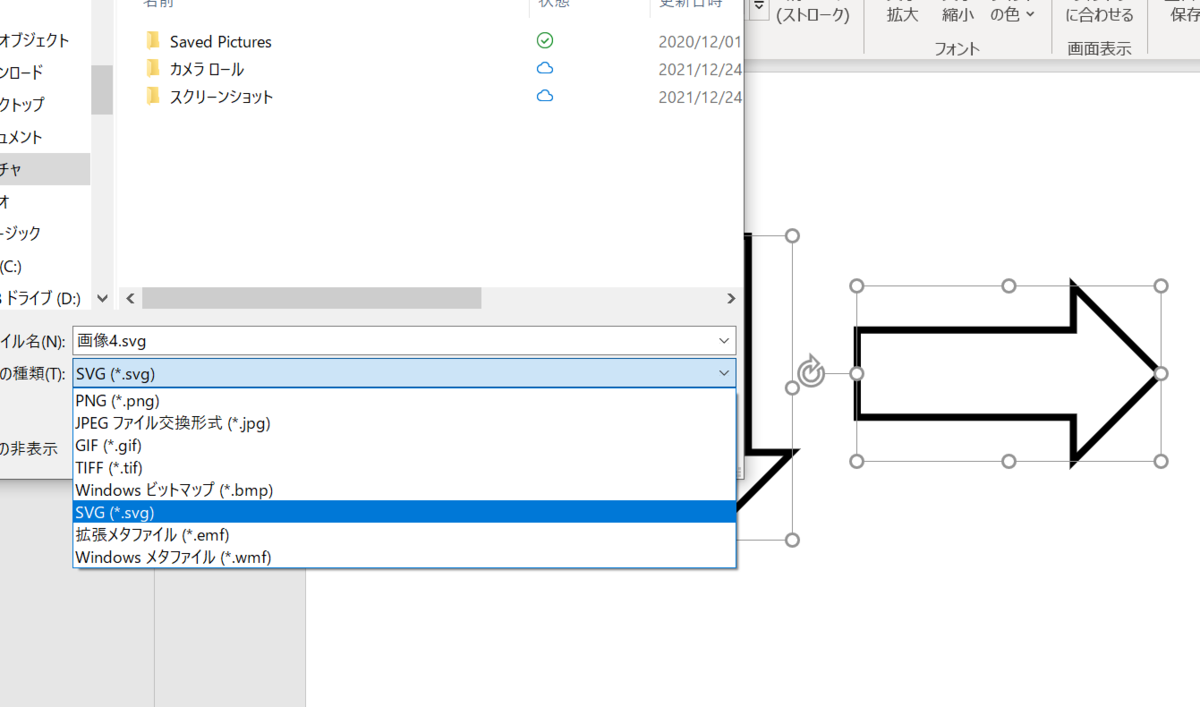
保存形式は.svgです。
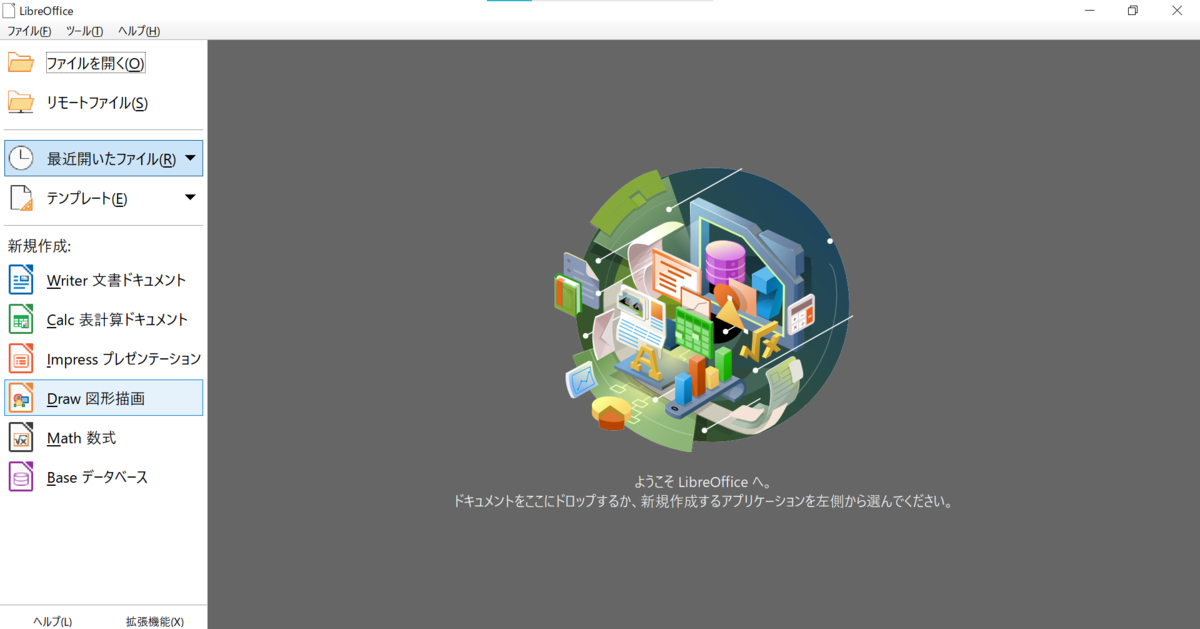
PowerPoint側でやることは終了。あとはLibreOfficeを使っていきましょう。
LibreOfficeで.epsとして保存
LibreOfficeを起動すると以下のような画面になります。Draw図形描画を選んでください。
真っ白い画面に飛んだら挿入で先ほど保存した図を入れましょう。大きさとか調整したらファイル→エクスポート。
拡張子は必ず.epsにしてください。
これで終わりです。あとはいつも通りTex側で貼り付けてあげてください。
卒論終わり次第、いろいろ覚書追加します。今日はこれが上手くいった嬉しさから更新しました(笑)
機械学習の検証(リーク、混同行列)について
こんにちは、Chihoです。
今日はインターンで機械学習の検証をやる機会があったのでその復習。
モデルとかちょっと触れたことはあっても検証をちゃんとやったことないのでいい勉強になりました。それでは行きましょう!
リークとは
本来考慮すべき点が漏れていることを言います。
今回検証した例では学習用データ、予測データに分けた時に学習用データに含まれているものが予測データに含まれていないか確認しました。
学習用データにすでに入っていればそりゃ正解するわな…って感じですね。
ほかにも予測データの要素内に答えが混じっていないか、未来を予測するのに今分からない、未来で分かる情報が入っていないかなどを考えます。
これをやらないとモデル構築して予測しても正しいものにはなりませんね。
混同行列とは
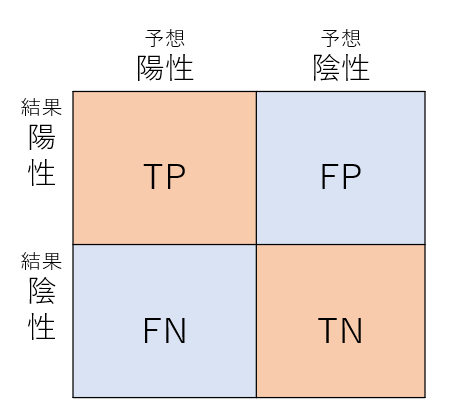
ここでは「インフルエンザが陽性か、陰性か」のような分類が2つだけのパターンを説明します。ちなみに多クラス分類についても混同行列は対応しています。
この予測は陽性、陰性の2つのパターンのみに分類されると思われがちですが、実は4つに分類できます。
真陽性(TP)
今回の例で言うならば、インフルエンザの陽性だったと予想して、実際に陽性だったパターンがこれに当たります。
真陰性(TN)
こちらはインフルエンザが陰性だったと予想して、実際に陰性だったパターン。
真陽性、真陰性については予想と答えはあっています。
偽陽性(FP)
ここからは予想が違ってきます。
偽陽性ではインフルエンザが陽性だと予想したのに実際は陰性だったパターンが当てはまります。
偽陰性(FN)
こちらでは陰性だと予想したのに陽性だったパターン。感染症で言えば一番危ないやつですね。
一口に合ってる、合ってないといってもこれだけのパターンが考えられます。
以下はまとめの図。
精度の評価
続いてそのモデルの精度を評価していきます。
精度の評価なんて正解率を計算すればいいじゃん!って思う人もいるかもしれませんがそれは要注意。
インフルエンザの例を使うなら「今の時期、インフル流行ってるし風邪っぽいやつはみんなインフルでいいよね!」って言ってるやつがいたらどうでしょうか…

確かに流行ってるのでおそらく正解率は高いかもしれません。でも偽陽性、つまり適当に陽性だと言われたけど実際には陰性の人もいるわけです。どこかに偏りがあるとそのモデルは学習時に偏った傾向をつかんでそれのみで分類してしまうかもしれません。その時に以下の3つの評価指標が役に立ちます。
Accuracy(正解率)
これが一番しっくりくるやつ。
どれだけ予測と事実が一致してるかの指標です。
(TP + TN) / (TP + TN + FP + FN)
普通に全体で正解したやつを割ればいい。
Recall(再現性)
インフルエンザの例で言うと、陽性の人を予測の時点でどれだけ当てられたかになります。
結果的に陽性だった人のみ考えます。その中から予想の時点で陽性だった人の割合を算出する指標です。
TP / (TP + FN)
Precision(適合性)
今度は陽性だと予想した中で本当に陽性だった人を考えます。
適当にみんな陽性としてしまった場合、ここの割合が低くなるのでモデルが不適切であるということが分かります。
TP / (TP + FP)
基本この3つのバランスを見て検証を行うようです。
とりあえず今日はここまで。次回くらいに実際にPythonで書いて動かしてみます。